Concepts
Modernize .NET and SQL Server Development and Test
In this post we take a look at Windocks 2.0 with integrated database cloning and web UI. Database clones enable delivery of terabyte class...
In this article we take a look at the understandable human tendancy to do "what worked last time" for enterprise data access. Unfortunately, in a data centric world, doubling down on storage carries obvious problems. We take a look at a new approach.
In a data driven world enterprises are grappling with the need for increased access to production data, while enhancing data security, and achieving cloud-native agility and economy. Unfortunately, technical and organizational issues between applications and data storage present challenges to these goals.
While Windows and Linux dominate modern computing, storage systems remain a bastion of UNIX and proprietary block and object storage systems. Organizational and technical barriers often lead DBAs and developers to use database backups resulting in “data sprawl” with data replicated for dev/test use.
In this article we look at the issues involved in data access, and the trade-offs between storage based and application-driven data access and delivery.
It’s understandable that strategies for data access often start with data storage, and two storage architectures dominate discussions today. In the first case Tier 1 storage arrays connect with Windows or Linux hosts with iSCSI or fiber channel connections, with data provided to locally hosted Virtual Machines. Data access involves maintaining a complex set of scripts. These systems work well until someone forgets to detach a database, and the system breaks down.
A new category of secondary storage is growing fast, with a dual focus of improving backup and recovery and data access. Data access is improved through restful APIs and improved UI, and data can be distributed on the network via SMB and NFS support.
While these two architectures are popular for private data centers, their fit in the public cloud is challenged by the growing use of Cloud Services. Public Clouds are increasingly focused on Services, and storage appliances are limited to run only as infrastructure (IaaS) level Virtual Machines.
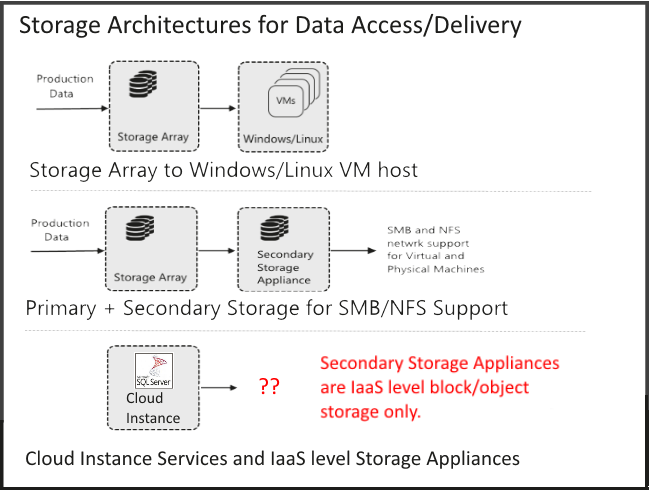
Secondary storage appliances play an important role in storage, and particularly for backup and recovery. But, generally fall short for improved data access. Problems include high cost of ownership, inadequate and admin driven data access, and lack of support for industry standard workflows and APIs.
Secondary storage appliances will never deliver cost effective data access. Leaders such as Delphix come with a minimum starting price of $250,000 or more, and even innovators in the space such as Actifio come with a minimum monthly VM cost of $5,000. These companies are organized for legacy support and decision-making, with an expensive tops-down sales processes.
Cost of Ownership issues are compounded with the cost of storage administrators required to run and maintain these proprietary systems. Secondary storage vendors rely on vendor-specific APIs for more vendor lock-in, and run on UNIX and proprietary block or object storage systems. While it’s possible to run on the public cloud they are expensive, and are limited to running as IaaS VMs.
These approaches are best understood as “lift and shift” of enterprise storage to the cloud, and offer little or no support for Cloud based Services (AWS RDS, Azure Instances). Support for Docker containers is badly lagging, and will continue to be limited to IaaS level use.
Cloud-native computing delivers automated infrastructure that scales according to application and developer needs. Containers, and now Kubernetes clusters, automate networking and compute, so shouldn’t we also automate storage for data access? The Cloud Native Computing Foundation (CNCF) clearly agrees, and has several projects aimed in this direction.
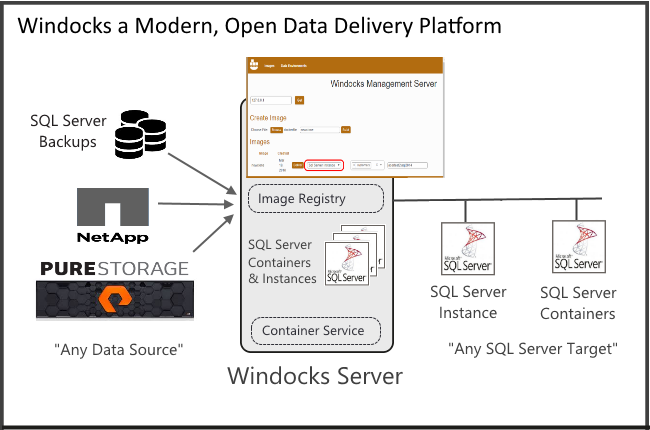
Windocks is an independent port of Docker’s source to Windows, and for three years has combined SQL Server containers with database cloning to modernize data access and delivery. Customers automate delivery of data environments for dev/test and QA, and reporting and BI. Windocks is partnering with Pure Storage and other Tier 1 storage firms to deliver SQL Server data access and delivery.
This month Windocks releases support for any storage array, with data delivery to any SQL Server target. A growing number of cloud variety of SQL Server instances are also supported. Windocks is popular for data migration, and upgrade testing of SQL Server data on SQL Server 2017 on Linux containers.
Storage systems play a vital function with flash based performance of production workloads, deduplication, and backup and recovery. Enterprise data access needs, however, won’t be achieved by doubling down on yet more storage appliances. Smart architects and decision-makers will focus on application and cloud-native data access that abstracts the underlying storage. Windocks is pioneering this with improved economy, openness, and security.
Windocks simplifies sourcing data from any storage array, cloud service, or infrastructure, delivering data to the application environment of your choice. Windocks supports all SQL Server containers and instances, and will add MySQL and other data environments later in 2018. Windocks starts at $199/month for small teams, and runs wherever Windows servers are supported, both on premises or public cloud. Windocks is growing rapidly and particularly for those exploring migration to SQL Server 2017 on Linux containers.
Start your own exploration today by downloading the free Windocks Community Edition.
In this post we take a look at Windocks 2.0 with integrated database cloning and web UI. Database clones enable delivery of terabyte class...
In this article we take a look at Windocks new support for creating SQL Server database clones that are delivered to Microsoft's official Docker SQL...
In this article we take a further look at the automation being used with SQL Server containers to deliver daily access to production data for...